Headroom
An approval firewall for AI agents — and the measurement layer that tells you whether your human oversight is any good.
New to the idea? Read it in plain terms →
The problem
Companies are giving AI agents real power — deploying code, running shell commands, moving money, touching production. The standard safety net is a human-in-the-loop approval gate: risky actions pause for a person to approve or reject, and everyone running agents builds some version of it. The flaw nobody measures is that the reviewer isn’t an infinite, reliable oracle. People fatigue. By the 300th routine approval, a reviewer is rubber-stamping — and the one dangerous action buried in the stream sails through. Most teams set their escalation threshold by gut feel, with no measured sense of where their reviewers actually stop being reliable.
The insight
Human oversight has a capacity. Past a point, more review makes a system less safe — attention is finite, and every routine escalation spends the attention the truly dangerous action will need. The field treats oversight as a classification problem (which action is risky?); the harder, rarely-measured part is the human — how much load a reviewer absorbs before judgment degrades, and how much reviewers even disagree about what counts as risky. That’s a measurement gap, not a classification gap.
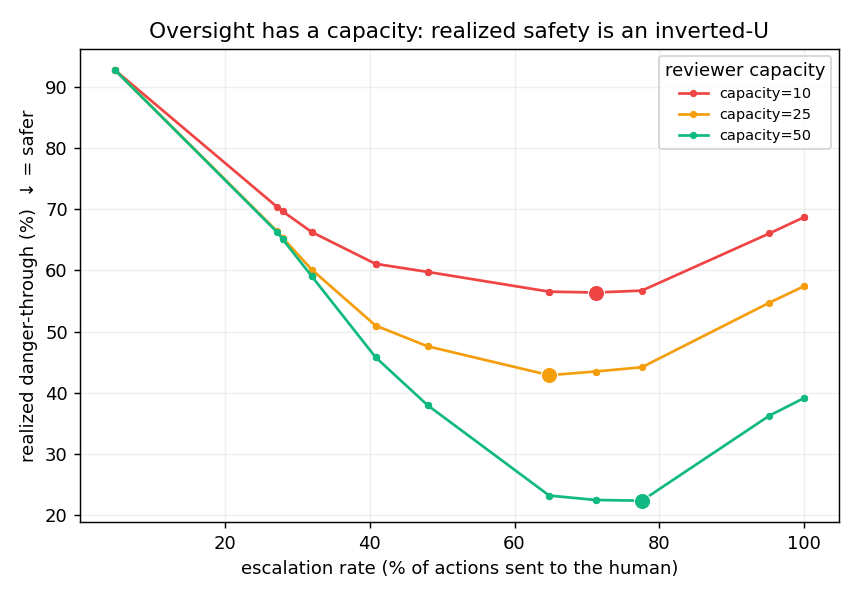
What I’m building
Headroom is a human-in-the-loop firewall for AI agents — but the real product isn’t the gate (frameworks give you that for free); it’s the measurement layer on top. It measures a team’s own reviewers: where their judgment degrades under load, how much they disagree about what’s even risky, and what their actual reliability curve looks like — then turns that into a concrete, data-backed escalation policy instead of a guess.
How it’s measured
Reviewers label a continuous, randomized stream of agent actions while I log every decision against cumulative load. Three signals, in order of how hard they are to argue with:
- Reaction time / hesitation — climbs as load builds. It needs no ground-truth labels, so it sidesteps the “risk is subjective” objection entirely.
- Accuracy under load — agreement with a reference label as fatigue sets in (measured relative to a reference, not claimed as objective truth).
- Reviewer disagreement — because everyone labels the same items, how much your reviewers diverge on what even counts as risky. Usually the surprise.
Together these recover the reviewer-reliability curve and its capacity point — roughly how many reviews someone sustains before judgment drops — the number your escalation policy should respect: where to set the threshold, when to rotate, when to add a second reviewer.
Use it
Headroom runs as an MCP server, so your own agent — Claude Code, Cursor, or a custom one — routes its actions through the guard before it acts. ~4 lines of config:
{ "mcpServers": { "headroom": { "command": "python", "args": ["-m", "headroom.mcp_server"] } } }Or try it with zero install — live demo.
Why it matters
Every company adopting agentic workflows will run human oversight, and right now most are tuning it blind. Frontier labs are openly worried about exactly this — oversight bottlenecks, monitoring at scale, reviewer fatigue. As agents get more autonomous, the bottleneck stops being the agent’s capability and becomes the human’s capacity to supervise it. That’s the layer Headroom instruments.